MuZero, une approche fonctionnelle et intuitive
MuZero est un algorithme d’apprentissage par renforcement qui permet d’optimiser les actions prises pour atteindre un objectif donné. Son originalité réside dans sa capacité à se passer d’une modélisation explicite des règles de l’environnement : il apprend à les extraire et à les comprendre de manière implicite, à mesure qu’il s’entraîne.
Pour apprendre, l’algorithme prend des décisions et s’auto-ajuste en fonction des résultats. Comme un humain, s’il se trompe, il est pénalisé, et s’il a raison, sa prise de décision s’en trouve renforcée. Avec l’accumulation d’expérience, il peut donc devenir très rapidement – tout est relatif – performant dans le domaine qui lui est attribué. Cela peut être aussi bien un jeu de plateau comme les échecs ou le go, un jeu vidéo, ou encore la compression vidéo (ce qu’il fait, par exemple, sur YouTube).
Cependant, on peut se demander comment un algorithme peut ainsi généraliser ses retours d’information pour apprendre dans autant de domaines.
Ici, le but n’est pas de fournir une approche scientifique de MuZero – le papier de recherche l’explique déjà très bien – mais plutôt de développer une intuition de ce qu’il fait. Dans un second temps, il sera intéressant d’aller plus loin dans l’aspect technique (ce que j’appelle le “deuxième layer”). Pour l’instant, restons en surface.
Pour faire fonctionner MuZero, on définit d’abord un cadre et un ensemble d’actions possibles. Il est nécessaire que ce set d’actions soit fini, car s’il était infini, l’algorithme ne pourrait pas toutes les examiner et se retrouverait à effectuer une recherche interminable. Le temps d’exécution est donc contraint par l’espace des actions disponibles et par l’environnement dans lequel ces actions sont exécutées. Ainsi, la fameuse question sur “la vie, l’univers et le reste” impliquerait un nombre quasiment infini d’actions et un environnement lui aussi quasi infini, rendant la démarche irréaliste pour MuZero.
Mais alors, comment MuZero fonctionne-t-il concrètement ?
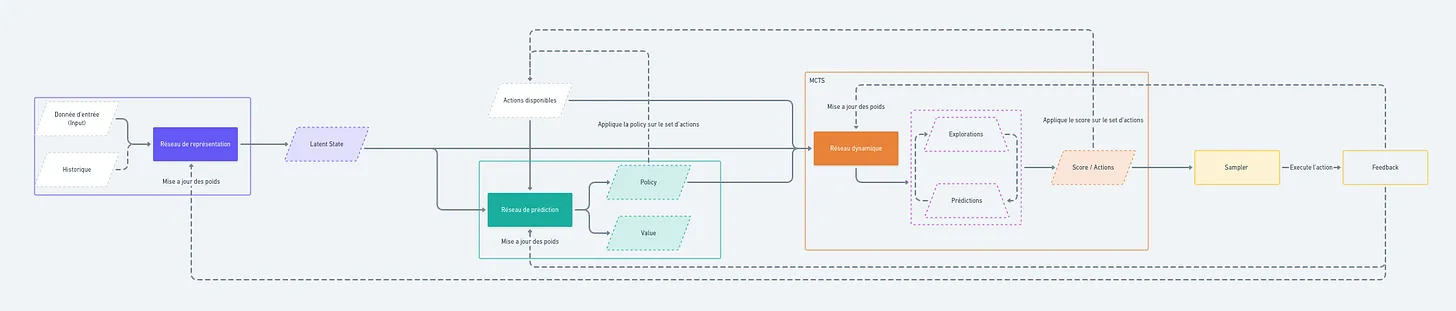
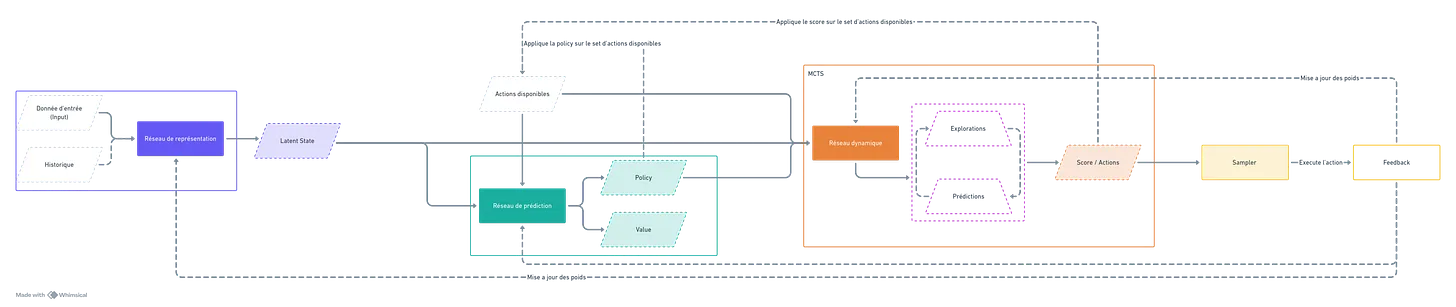
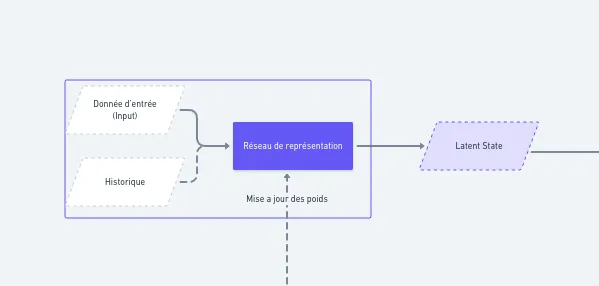
L’algorithme reçoit un input (une donnée d’entrée), qui correspond à une observation de l’état actuel, ainsi qu’un historique des actions précédentes et un set d’actions disponibles. L’état actuel, combiné à l’historique, est ensuite encodé par un premier réseau de neurones, appelé réseau de représentation. Ce réseau génère une représentation de l’état (un ensemble de vecteurs) qui prend en compte les choix passés et se perfectionne au fil des itérations.
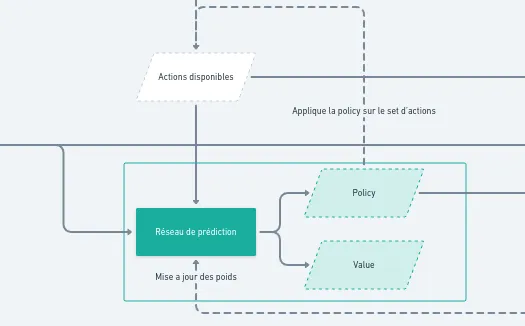
Ce premier réseau alimente ensuite un deuxième réseau, appelé réseau de prédiction. Celui-ci produit deux éléments : une value (ou valeur) et une policy (ou stratégie). La valeur indique le score optimal que le joueur (ou l’algorithme) peut atteindre s’il joue parfaitement depuis l’état actuel. La policy, quant à elle, est une distribution de probabilités sur l’ensemble des actions possibles, suggérant celles qui améliorent le plus les chances d’atteindre l’objectif. Ce deuxième réseau s’affine lui aussi progressivement, à mesure que MuZero acquiert de l’expérience.
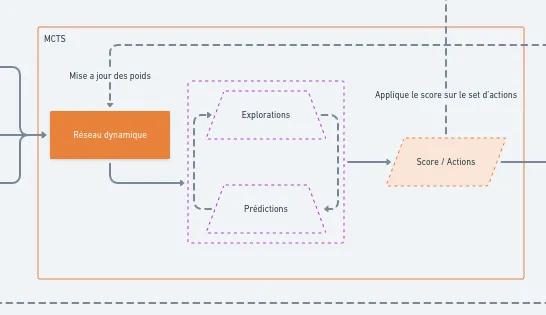
Mais il manque encore quelque chose d’essentiel. Si MuZero peut fonctionner dans autant de situations, c’est parce qu’il ne se contente pas d’appliquer un modèle fixe de l’environnement. Il construit sa propre vision de ce qui l’entoure, une sorte de représentation interne des conséquences de ses actions. Plutôt que d’apprendre des règles définies à l’avance, il s’ajuste en continu ce qui lui permet d’anticiper comment son univers évolue en fonction de ses choix.
C’est cette idée qui le distingue des autres algorithmes. AlphaZero, par exemple, connaît dès le départ les règles du jeu auquel il joue. MuZero, lui, n’a pas ce luxe. À la place, il prédit ce qui va se passer et affine son intuition à mesure qu’il engrange de l’expérience. Ce processus repose sur ses trois réseaux, qui s’adaptent en permanence grâce aux retours qu’il reçoit. Lorsqu’il agit, il compare ce qu’il pensait obtenir avec ce qui s’est réellement passé, et il ajuste ses modèles en conséquence.
En revanche, plus l’environnement est complexe, plus l’apprentissage est lent et gourmand en calcul. Il faut du temps, de la puissance et des milliers d’itérations pour qu’il trouve son équilibre. Pourtant, cette flexibilité est aussi son plus grand atout. Là où d’autres algorithmes sont enfermés dans des règles rigides, MuZero apprend à jouer avec les siennes. C’est ce qui lui permet de s’attaquer à des tâches aussi variées qu’un jeu de stratégie ou l’optimisation d’une vidéo.